Reddit Multi Code Decoder for obfuscated content
A userscript that automatically detects and translates encoded messages in Reddit comments, making hidden content instantly readable. Supports binary code and NATO phonetic alphabet patterns.
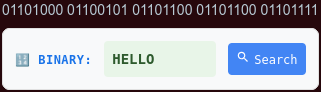
Screenshot of rendering of the translated binary code.
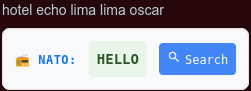
Screenshot of rendering of the translated NATO code.
Code repository for contributions and support
github.com/freebee9/reddit-multi-code-decoder-userscript
🚀 Features
- Multi-Format Detection: Automatically scans Reddit comments for multiple encoding types
- Binary Code: Sequences of 0s and 1s (e.g.,
01001000 01100101 01101100 01101100 01101111)
- NATO Phonetic: Alphabet sequences (e.g.,
Alpha Bravo Charlie)
- Real-time Translation: Converts encoded messages to readable text instantly
- Smart Combining: NATO sequences in same text are combined into single translation
- Centralized Search: Configurable search provider system (Google, Bing, DuckDuckGo)
- Text Selection Search: Select any text in comments and get a popup to search it (dismiss by clicking elsewhere)
- Cross-Platform: Works on both new Reddit and old Reddit
- Dynamic Loading: Handles lazy-loaded comments and expansions
- Performance Optimized: Unified processing with minimal impact on browsing experience
📋 Requirements
- Browser with userscript support (Chrome, Firefox, Safari, Edge)
- Userscript manager extension:
- Violentmonkey (recommended)
- Tampermonkey
- Greasemonkey
🔧 Installation
Install a userscript manager:
Install the script:
- Copy the userscript code
- Open your userscript manager
- Click "Create new script" or "+" button
- Paste the code and save
Enable the script:
- Make sure the script is enabled in your userscript manager
- Visit any Reddit page to start using it
📖 How It Works
Multi-Format Pattern Detection
The script looks for various encoding patterns:
Binary Code:
01001000 01100101 01101100 01101100 01101111
NATO Phonetic Alphabet:
Alpha Bravo Charlie Delta Echo
Lima India Mike Alpha
Translation Process
- Unified Scanning: Single pass detects all encoding types in comments
- Format-Specific Conversion:
- Binary: Converts 8-bit groups to ASCII characters
- NATO: Maps phonetic words to letters (Alpha→A, Bravo→B, etc.)
- Smart Validation: Only shows translations for valid, meaningful text
- Combined Results: NATO sequences in same text are joined into single translation
Examples
Binary code:
Input: 01001000 01100101 01101100 01101100 01101111
Output: 🔢 Binary: "Hello" [🔍 Search]
NATO phonetic:
Input: Alpha Bravo Charlie Delta Echo
Output: 📻 NATO: "ABCDE" [🔍 Search]
🎯 Usage
- Browse Reddit normally - the script works automatically
- Look for translation boxes - they appear below comments containing encoded content
- 🔢 Blue boxes for binary translations
- 📻 Blue boxes for NATO phonetic translations
- Click the search button - instantly search the translated text using your configured provider
- Select text for search - highlight any text in comments to get a search popup (click anywhere to dismiss)
- Expand comments - the script will scan newly loaded content for all encoding types
⚙️ Technical Details
Supported Reddit Layouts
- New Reddit (reddit.com)
- Old Reddit (old.reddit.com)
- Mobile Reddit layouts
Encoding Format Requirements
Binary Code:
- Must be valid 8-bit binary (multiples of 8 characters)
- Should decode to printable ASCII characters (32-126)
- Minimum 2 consecutive 8-bit sequences required
NATO Phonetic:
- Must contain at least 2 valid NATO phonetic words
- Supports variations: Alpha/Alfa, Xray/X-ray
- Flexible separators: spaces, commas, periods, hyphens
- Case-insensitive matching
- Multiple sequences in same text are combined
Performance Features
- Efficient scanning: Uses TreeWalker for optimal DOM traversal
- Duplicate prevention: Marks processed elements to avoid re-scanning
- Lazy loading support: Monitors for dynamically added content
- Event-driven updates: Responds to comment expansions
- Text selection detection: Lightweight event handling for text selection
🛠️ Customization
Search Provider Configuration
The script includes a centralized search system supporting multiple providers:
// Switch to different provider
SEARCH_CONFIG.active.provider = "bing"; // or "duckduckgo"
// Change default search type
SEARCH_CONFIG.active.defaultSearchType = "webSearch"; // or "imageSearch"
// Add custom provider
SEARCH_CONFIG.providers.custom = {
name: "Custom Search",
webSearch: "https://example.com/search?q={{QUERY}}",
imageSearch: "https://example.com/images?q={{QUERY}}"
};
Detection Pattern Modification
Binary patterns:
const binaryPattern = /(?:\b[01]{8}\b[\s]*){2,}/g;
NATO patterns:
const natoPattern = new RegExp(/* dynamically generated from NATO_ALPHABET */);
Styling Customization
All decoders use unified styling for consistency:
container.style.cssText = `
margin: 8px 0;
padding: 12px;
background: #f8f9fa; // Unified theme
border: 1px solid #e0e0e0;
// Only icons and labels differ between decoder types
`;
⚠️ Known Limitations
False Positive Considerations
Binary Decoder:
- Current threshold: Minimum 2 consecutive 8-bit sequences (16 bits = 2 characters)
- Potential issue: Short random binary-looking patterns may trigger false positives
- Example:
01000001 01000010 would decode to "AB" and show a translation
- Mitigation: Script validates that decoded text contains only printable ASCII characters
- Future improvement: Consider increasing minimum threshold to 3-4 sequences for better accuracy
NATO Phonetic Decoder:
- Current threshold: Minimum 2 valid NATO phonetic words
- False positive risk: Low - well-calibrated threshold
- Example: Single word "India" (country name) won't trigger, but "Alpha Bravo" will
- Validation: Only recognizes official NATO phonetic alphabet words
Detection Accuracy
Binary Detection:
- Very short meaningful text (1-2 characters) might be dismissed as potential false positives
- Complex binary with mixed content may not be detected if interspersed with non-binary text
- Only detects space-separated or clearly bounded 8-bit sequences
NATO Detection:
- Requires exact spelling of NATO phonetic words (case-insensitive)
- Mixed languages or non-standard phonetic alphabets won't be detected
- Sequences with too many non-NATO words between phonetic words may be missed
🐛 Troubleshooting
Script Not Working
- Ensure your userscript manager is enabled
- Check that the script is active in the extension
- Refresh the Reddit page
- Check browser console for errors
No Translations Appearing
Binary Issues:
- Verify the binary code is in valid 8-bit format
- Ensure the binary translates to readable ASCII text
- Some binary sequences might be filtered out if they contain non-printable characters
- Very short sequences (1-2 characters) may be filtered to prevent false positives
NATO Issues:
- Need at least 2 valid NATO phonetic words
- Check spelling of phonetic words (Alpha, Bravo, Charlie, etc.)
- Multiple sequences in same comment are automatically combined
- Mixed or non-standard phonetic alphabets won't be recognized
Text Selection Popup Not Appearing
- Make sure you're selecting text within comment areas
- Try selecting longer text (minimum 3 characters)
- Check if other extensions are interfering with text selection
Performance Issues
- The script is optimized for performance
- If experiencing slowdowns, try disabling other Reddit extensions temporarily
🔄 Updates
Version History
- v0.3.0: Added NATO phonetic alphabet decoder with smart sequence combining, centralized search provider system
- v0.2.0: Added text selection popup feature for instant Google search
- v0.1.0: Initial release with binary detection and Google search integration
📄 License
This project is licensed under the MIT License - see the license text in the script for details.
MIT License Summary
- ✅ Commercial use allowed
- ✅ Modification allowed
- ✅ Distribution allowed
- ✅ Private use allowed
- ✅ No warranty provided
Made with AI ❤️ ;) for the Reddit community
