If you require website/game/app outsourcing services, please feel free to send your project requirements to my email.
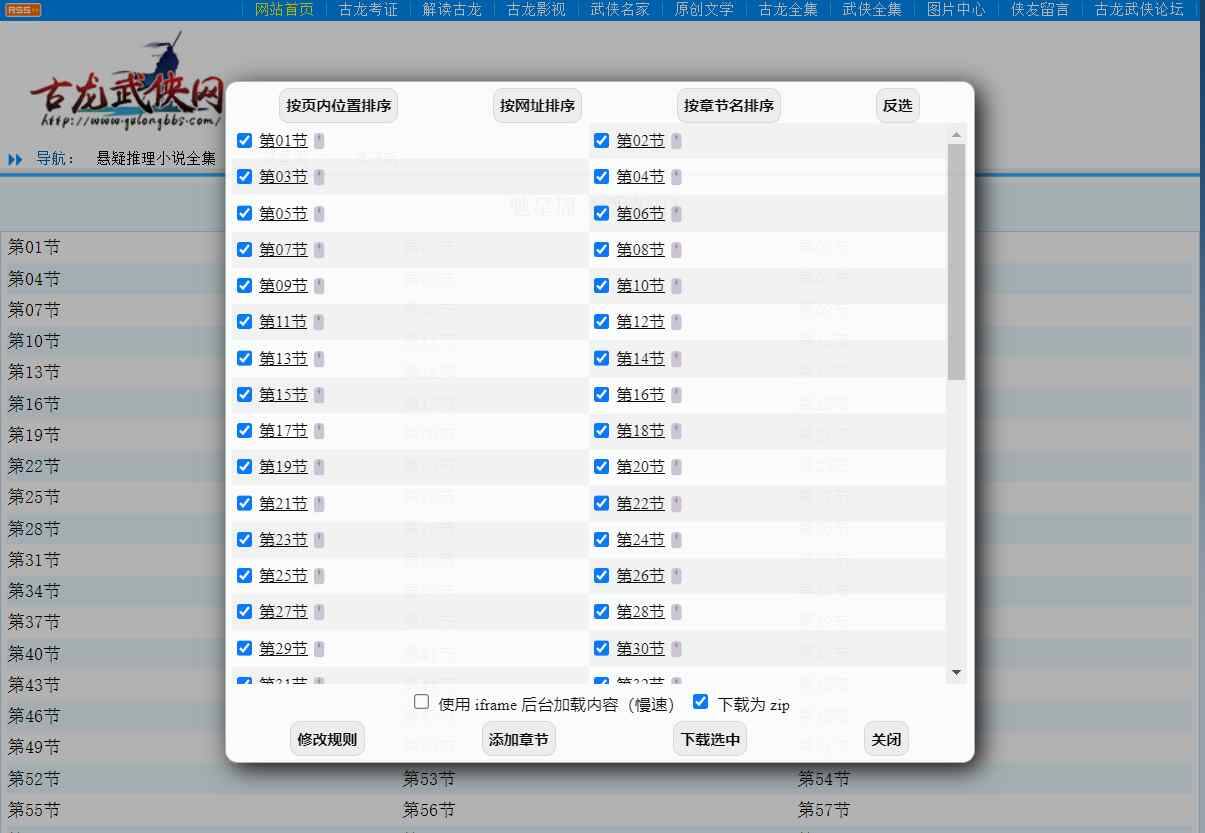
Script for download novel or text content on page.
Lightweight crawling script, used to download the main text content of the webpage, theoretically suitable for any non-Ajax novel website, forum, etc. without writing any rules for that.
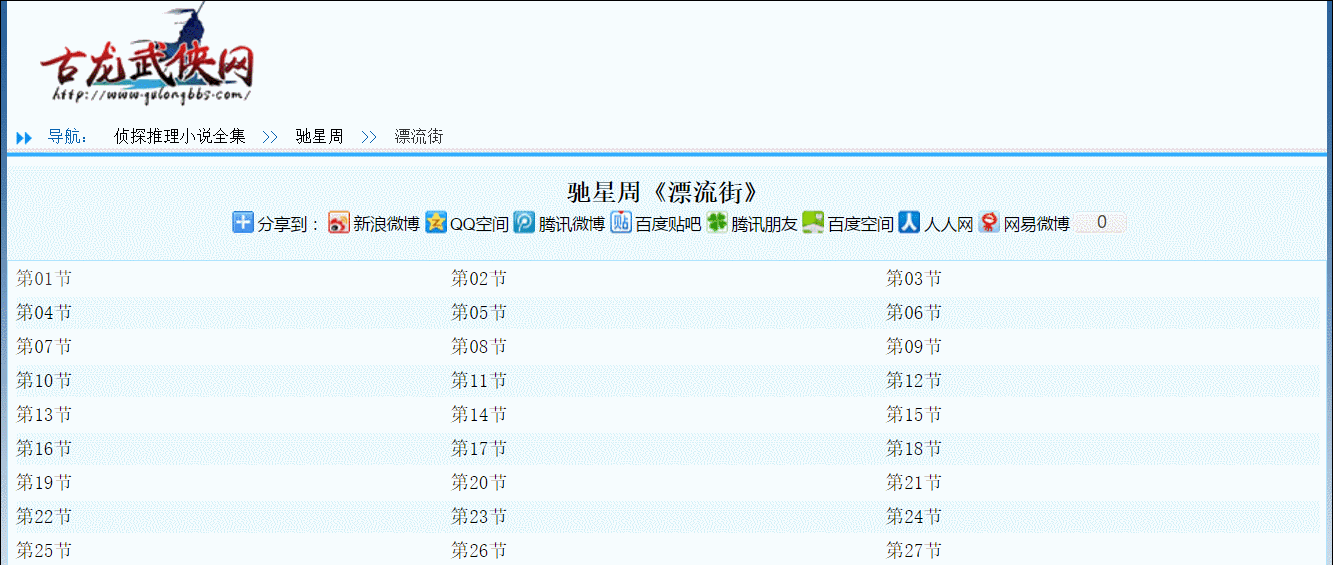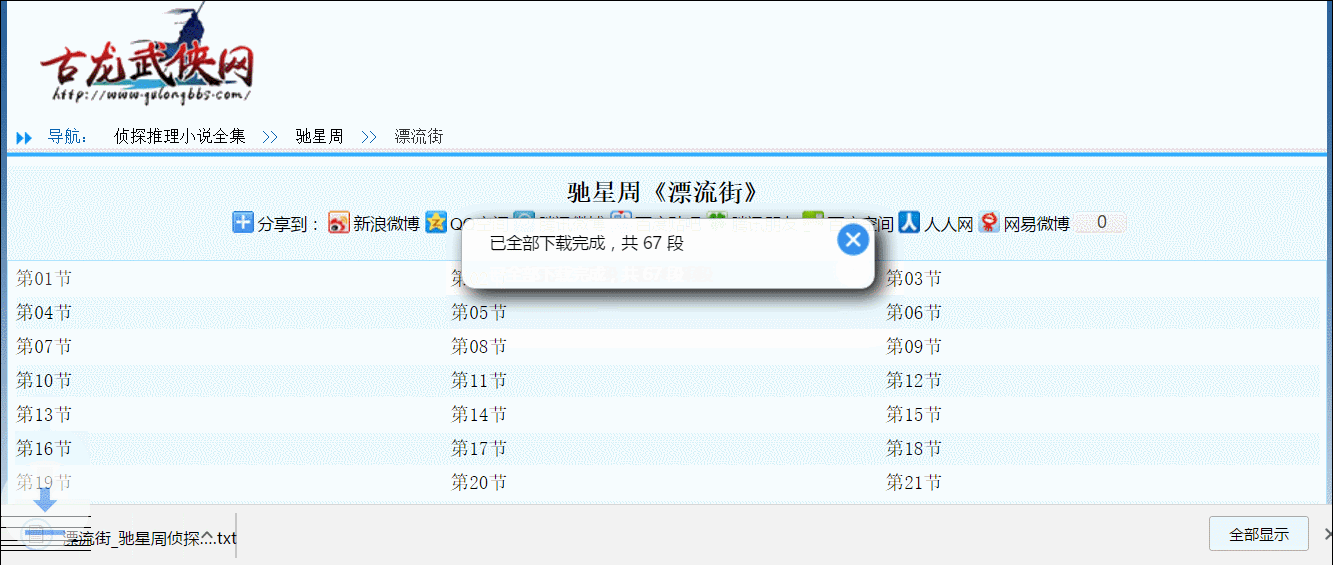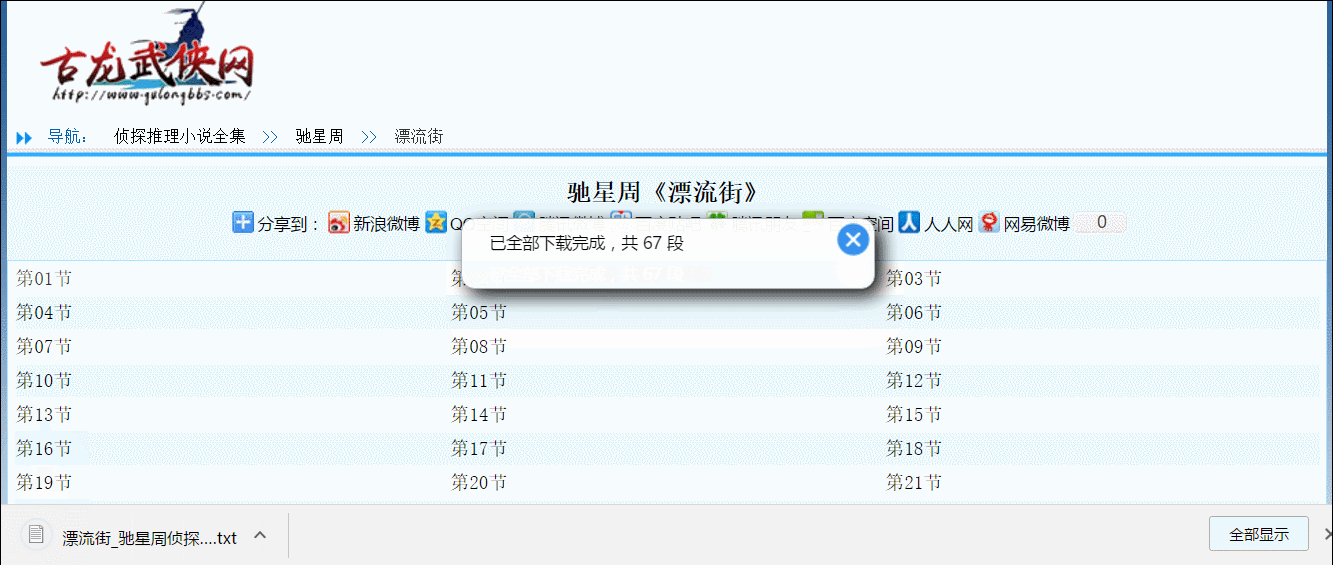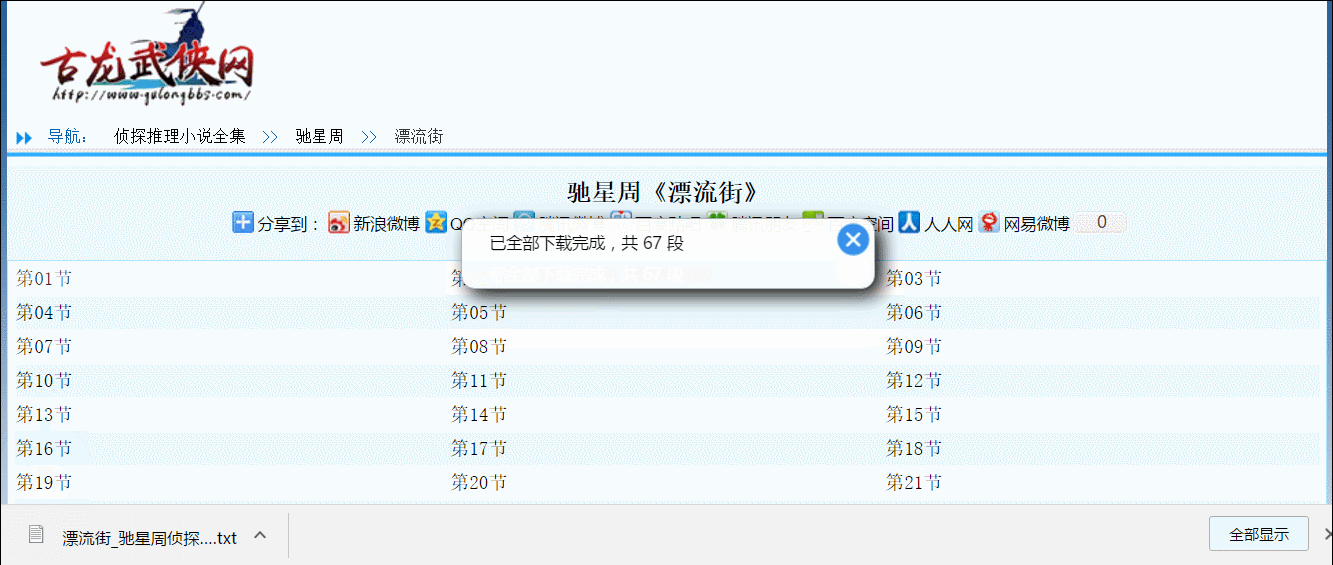
The script will automatically retrieve the main content on the page and download it.
If you are in the novel catalog page, it will traverse all the chapters, sort and save them as a TXT file.
Script Github
Stream links from cloud storage
Operation Instructions
- Open the novel catalog page, forum content page or any other page (just like current page).
- Press CTRL+F9 or click the command menu
- Press SHIFT+CTRL+F9 to download current single page (will not fetch catalog) only.
❤️Buy me a coffee if it helps you with PayPal.Me or Ko-fi.
Seek help from discord group

DownloadAllContent ZIP addon Save content as ZIP with separate TXTs for DownloadAllContent
About configuration items
The following functions need to be entered through the Greasemonkey command menu
- Custom download with directory range: such as :https://xxx.xxx/book-[20-99].html,https://xxx.xxx/book-[01- 10].html, which means download book-20.html to book-99.html, and book-01.html to book-10.html, [1-10] does not add 0
- Custom download via chapter text content or css selector: Just input the text content or css selector for one of the chapter links to be downloaded, and then you can concat the url replacement code and js code, e.g.
Windmill Gods01!02!03 -> means chapter like Windmill Gods01 & exclude whose title contains 02 or 03.
- Interference code: fill in the css selector of the interference code, such as
.mask,.ksam, which means to delete the element whose class is mask or ksam
- Reorder by title name: if true, sort all links on the catalog page by title name and save them in txt, otherwise, they will be sorted by page position order
Full format description
A certain chapter name/CSS selector (the selector can be followed by >> incoming item to add processing code) @@ The regular matching of the link is captured @@ The corresponding matching generates a replacement URL @@ Process and return the final text according to the crawled returned content data
Custom example
- po18, the chapter selector is
.l_chaptname>a, after inputting and downloading, it will be found that the body content cannot be downloaded through the url, the body is Downloaded through articlescontent, then you can follow @@articles@@articlescontent (@@ separated) to replace articles in the chapter url with articlescontent, The first 'articles' can use regularity, for example, @@articles(\d+)@@$1content means to replace "articles1", "articles2", etc in the link with "1content" "2content"
.l_chaptname>a @@ articles @@ articlescontent
- pixiv, the chapter selector of the site is
main>section ul>li>div>a, no need to replace the link, so after Two items(links&replace) are left blank, there are 6@ after, the content is in the meta, you need to customize the code to extract the content item of the meta-preload data. "data" means the document of page that get, use data.body.innerText to get text if the api return is text only.
main>section ul>li>div>a @@@@@@ var noval=JSON.parse(data.querySelector("#meta-preload-data").content).novel;noval[Object.keys(noval)[0]].content;
- 红薯中文网
ul#lists>li>>let href=item.getAttribute("onclick").replace(/.*(http.*html).*/,"$1"),innerText=item.querySelector("span").innerText;return {href:href,innerText:innerText};@@@@@@let rdtext=data.querySelector('div.rdtext');let sc=data.querySelector('div.ewm+script');if(sc&&rdtext){let code=sc.innerText.replace(/for\(var i=0x0;i<words.*/,"window.words=words;");eval(code);[].forEach.call(rdtext.querySelectorAll('span[class]'),span=>{let id=span.className.replace(/[^\d]/ig,"");span.innerText=words[id]}),rdtext.innerText};
- yuyan
https://yuyan.pw/novel/xxx/[xxxxxxx-xxxxxxx].html@@@@@@var c=data.querySelector('body>script:nth-of-type(8)').innerHTML.match(/var chapter =(.*?);\\n/)[1];eval(c).replaceAll("<br />","");
- 翠微居
.chapter-table>a@@@@@@fetch(data.querySelector("div.box-border>script").innerHTML.match(/\/chapter\/(.*?)"/)[0]) .then(response => response.text()) .then(d => {eval("window.txtObj="+d.match(/_txt_call\((.*)\);/)[1]);for(k in txtObj.replace){txtObj.content=txtObj.content.replaceAll(txtObj.replace[k],k)}cb(unescape(txtObj.content.replace(/&#x(.*?);/g,'%u$1')));});return false;
- 知乎盐选
[class^=ChapterItem-root]>>let a=document.createElement("a");let pre=`https://www.zhihu.com/market/paid_column/${location.href.replace(/\D*(\d+)$/,"$1")}/section/`;a.href=pre+JSON.parse(item.dataset.zaExtraModule).card.content.id;a.innerText=item.querySelector("div").innerText;return a;
Test case






