
Συζητήσεις » Greasy Fork Ανατροφοδότηση
Lang Filter for Discussion Search is Broken
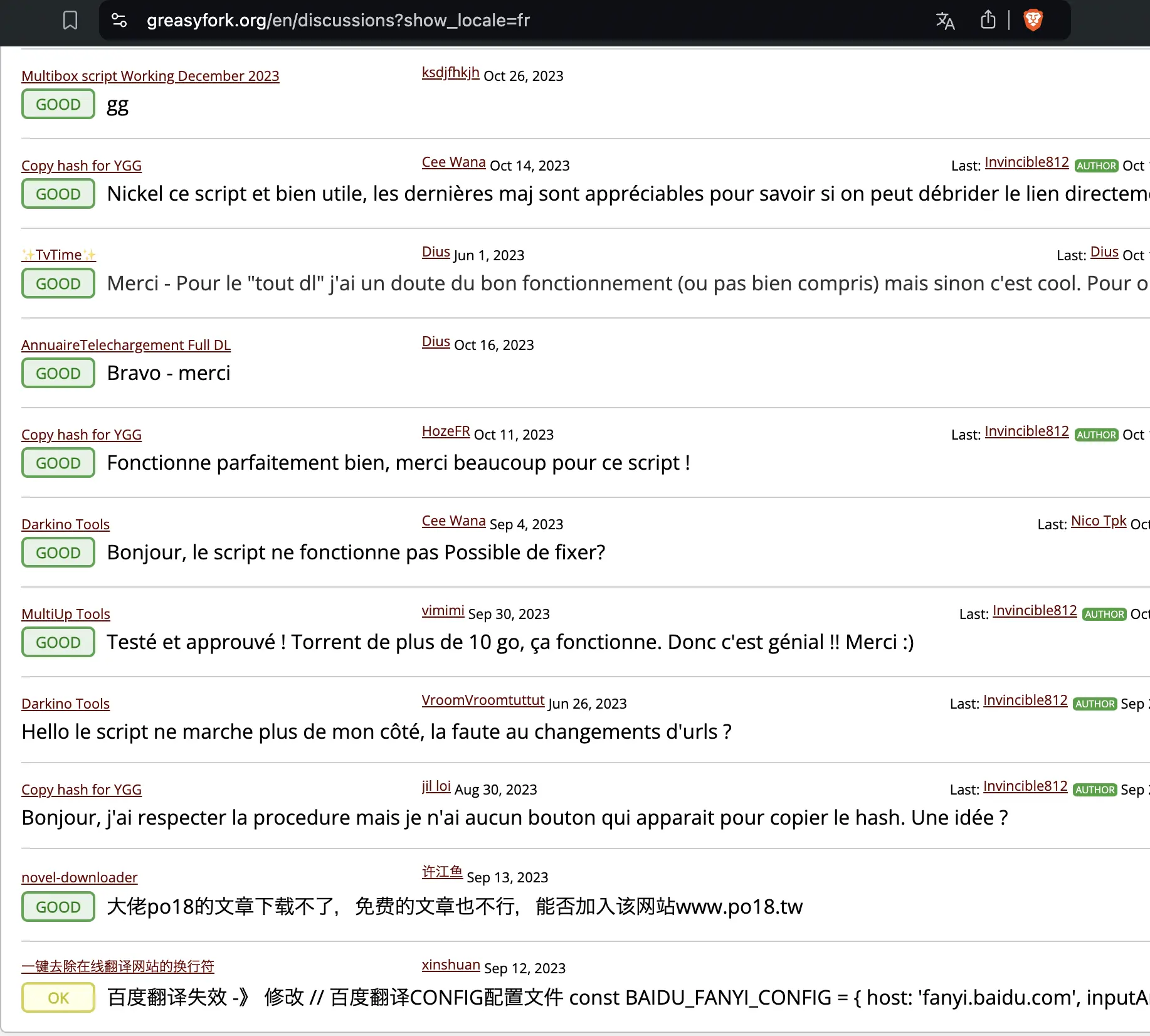
I can see that generally, it does work, for example https://greasyfork.org/en/discussions?show_locale=fr is almost all French language discussions.
Language detection is done by https://detectlanguage.com/. That has a demo box if you want to see what kinds of results you're getting. I can see it fails horribly for discussions like this, probably because it's a mix of Chinese characters and Latin.
I can see that generally, it does work, for example https://greasyfork.org/en/discussions?show_locale=fr is almost all French language discussions.
Language detection is done by https://detectlanguage.com/. That has a demo box if you want to see what kinds of results you're getting. I can see it fails horribly for discussions like this, probably because it's a mix of Chinese characters and Latin.
The encoding of some characters in Chinese and Japanese is the same. misidentified
@Jason Lang Filter for Discussion Search is Broken.
https://greasyfork.org/en/discussions?show_locale=ja
To be honest, I don't understand how do you do the language detection for the comments.
If you cannot find a proper way to filter comments by language, you might just remove this feature.
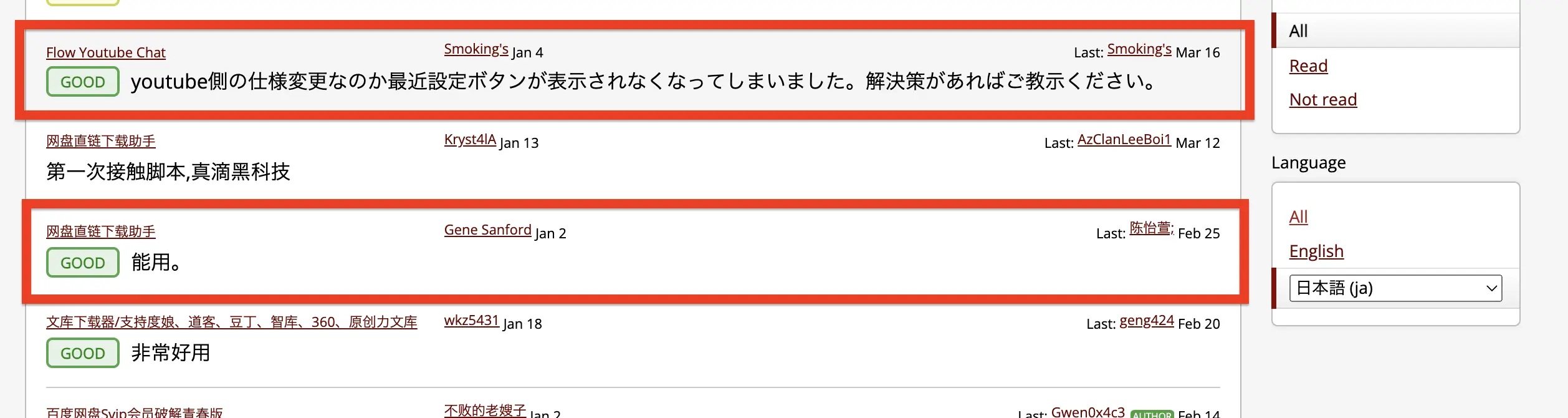
As the screenshot suggested, Chinese comments are wrongly recognized as Japanese comments.
一点小小的错误罢了,正常。不要太过激动
As it can detect Chinese comments correctly, can you make a filter for the Japanese comments?
( Detected as (Japanese+Chinese) - Detected as Chinese = Detected as Japanese )
I don't know Japanese or Chinese so I can't differentiate between kanji and Chinese characters. I can look into what detectlanguage.com is saying if you give me some concrete examples. Then potentially I could had some heuristics based on what that says and other factors.
Language detection is done by https://detectlanguage.com/. That has a demo box if you want to see what kinds of results you're getting. I can see it fails horribly for discussions like this, probably because it's a mix of Chinese characters and Latin.
After trying using the website demo, I think the actual issue is not that difficult to resolve.
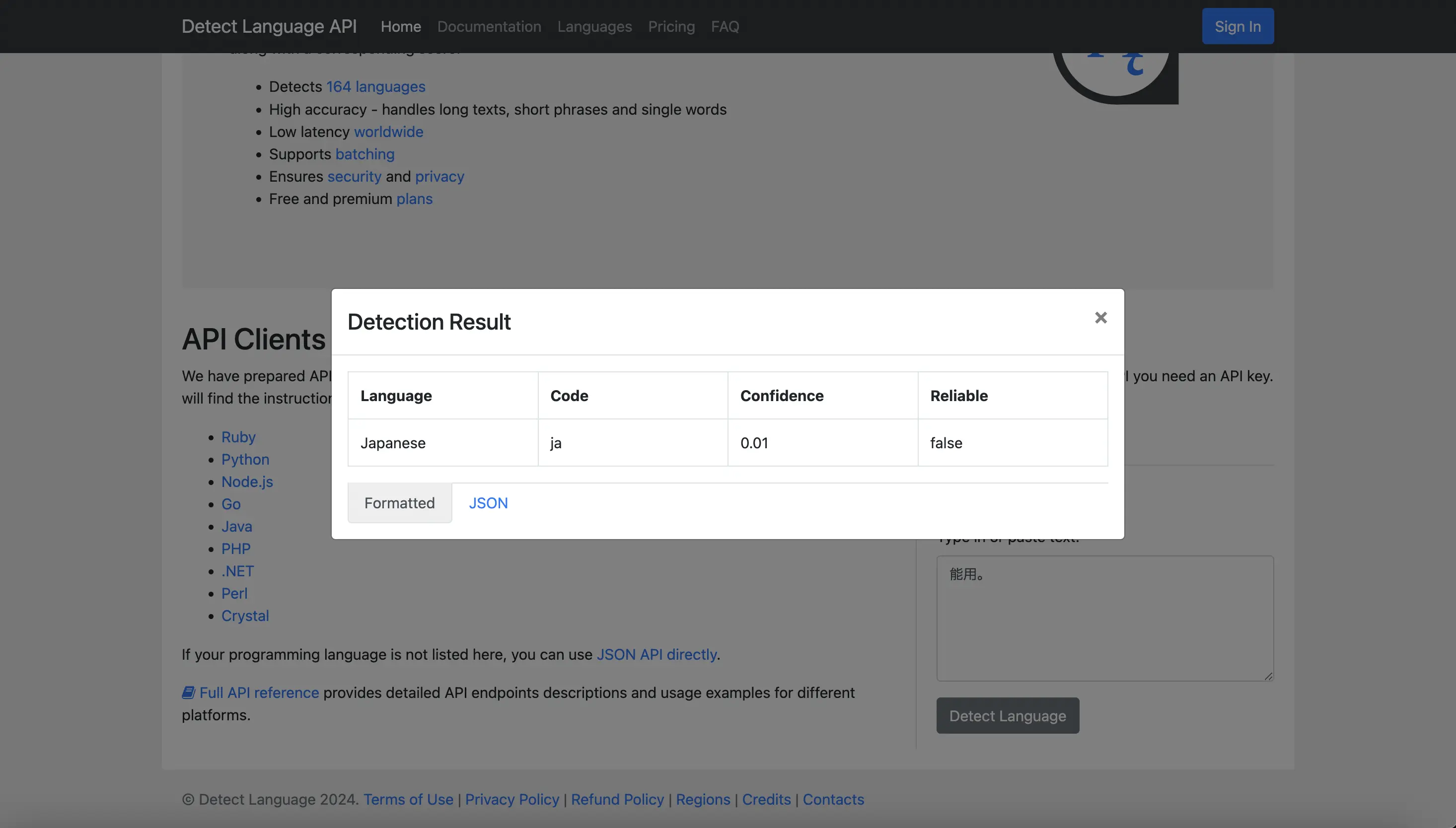
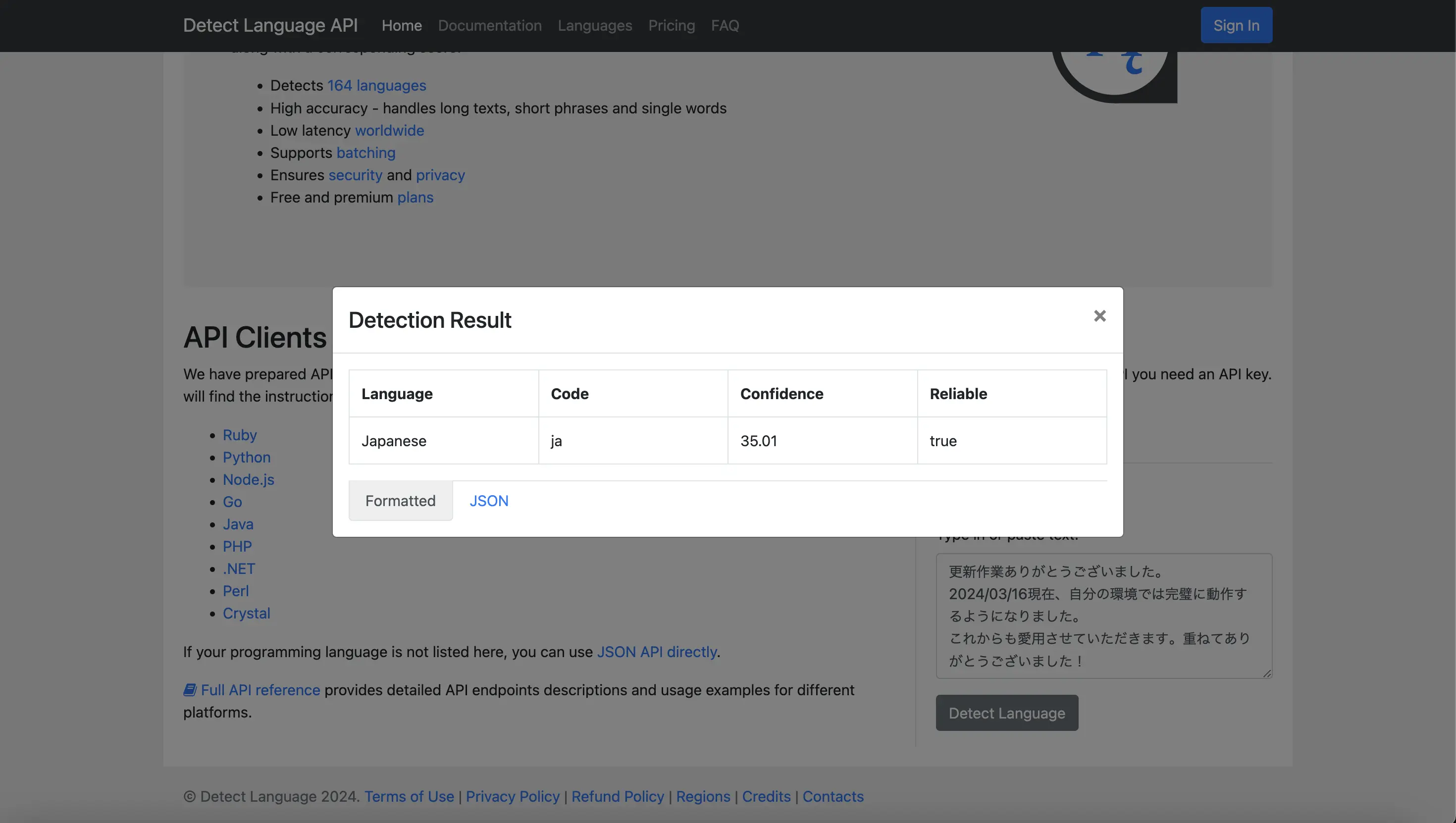
You can see that, there is a Confidence value and Reliable boolean in the result.
If it is considered as not reliable, you should filter them out from the results.
The samples I used above:
Japanese - https://greasyfork.org/en/scripts/411442-flow-youtube-chat/discussions/220713
Chinese - https://greasyfork.org/en/scripts/436446/discussions/220390
One more example - https://greasyfork.org/en/discussions/requests/248623
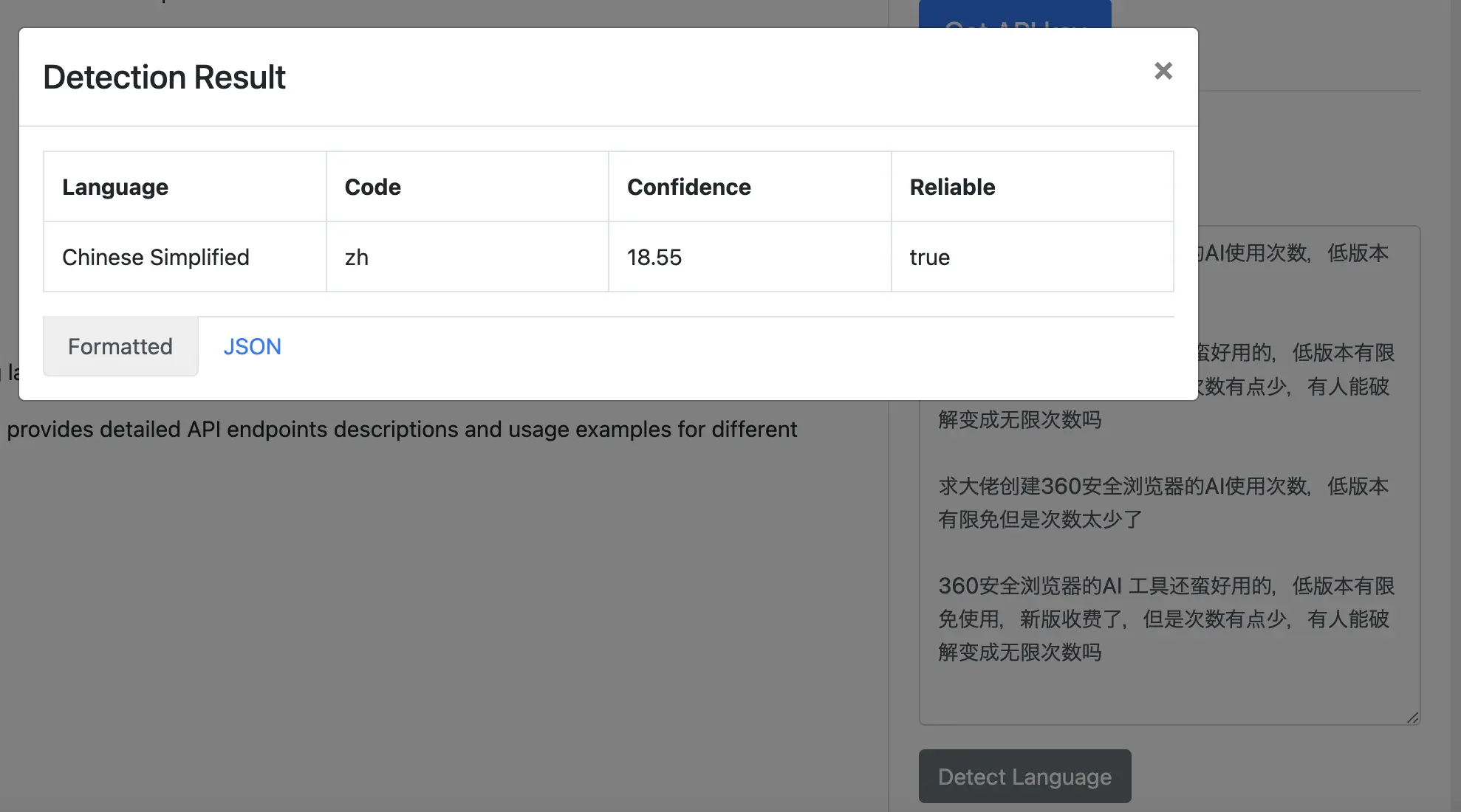
In this case, https://detectlanguage.com/ can detect it as Chinese Simplified with true reliable
But it is shown in the https://greasyfork.org/en/discussions?show_locale=ja

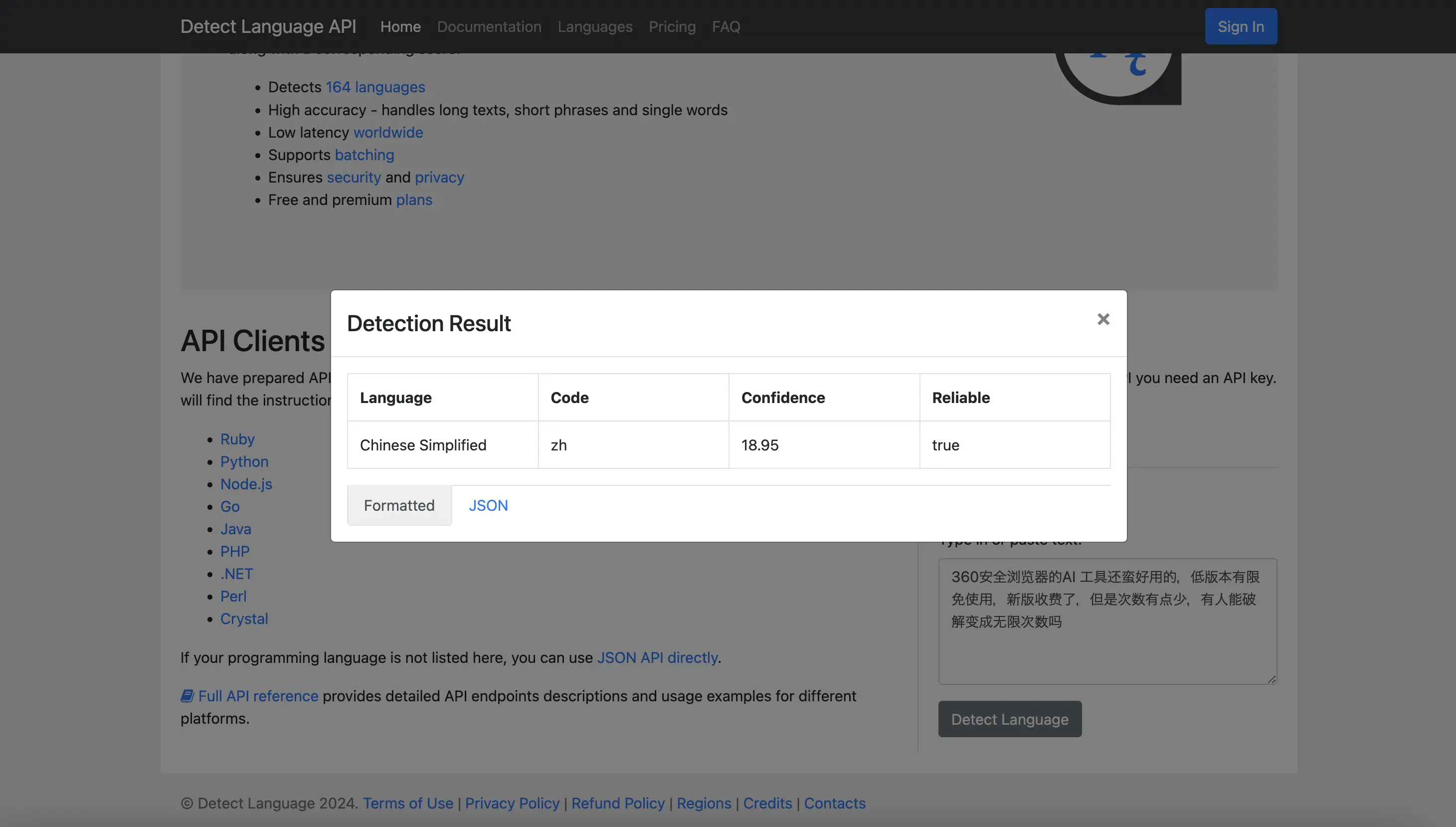
I think this is not the issue in detectlanguage. There should be something wrong in GreasyFork's implementation.
I don't know Japanese or Chinese so I can't differentiate between kanji and Chinese characters. I can look into what detectlanguage.com is saying if you give me some concrete examples. Then potentially I could had some heuristics based on what that says and other factors.
It is understandable that it might be difficult for the detection to detect whether it is Chinese or Japanese since both languages share some kanji characters in common. However, as per the detection demo result, even it is classified the Chinese sentences wrongly as Japanese, the reliable value would give false. In this case, the text should not be classified as Japanese.
Example Text:
"第一次接触脚本,真滴黑科技" (https://greasyfork.org/en/scripts/436446/discussions/222450)
If it is detected by Human, we can say with 100% confidence that it is Simplified Chinese.
But for API, even it cannot tell it is Simplified Chinese, it still shows the result with reliable:false
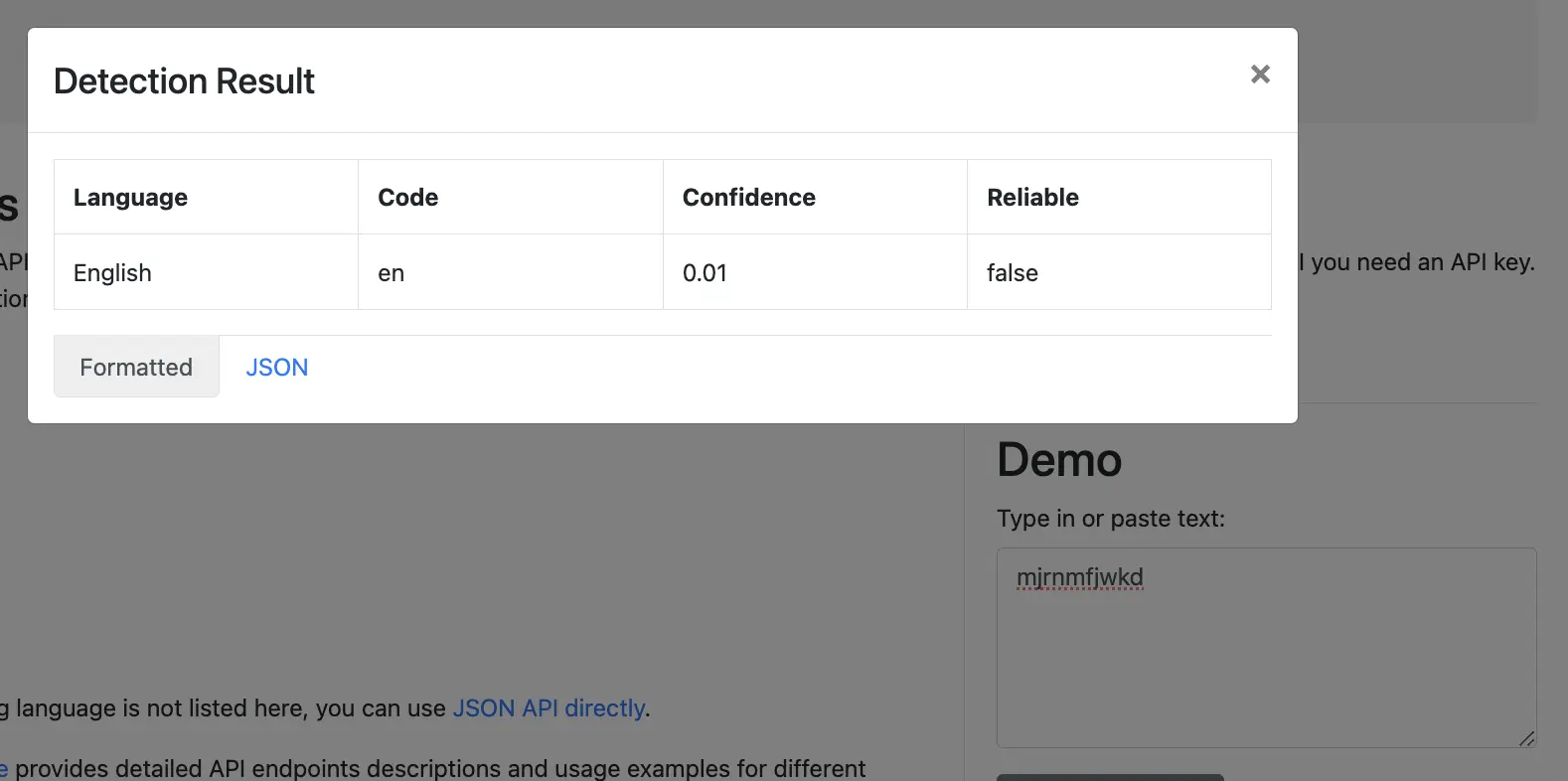
Result from DetectionLanguage for the above text:
{ "data": { "detections": [ { "language": "ja", "isReliable": false, "confidence": 0.01 } ] } }
OK, I believe I see the issue. It's supposed to take into account both the title and the text of the discussion, but it's only taking the title right now. For https://greasyfork.org/en/discussions/requests/248623, if you pass just the title to detectlanguage, it returns both Japanese and Chinese, but Japanese is "reliable".
Great!
For https://greasyfork.org/en/discussions/requests/248623, if you pass just the title to detectlanguage, it returns both Japanese and Chinese, but Japanese is "reliable".
It is fine for just a few of cases of false detection.
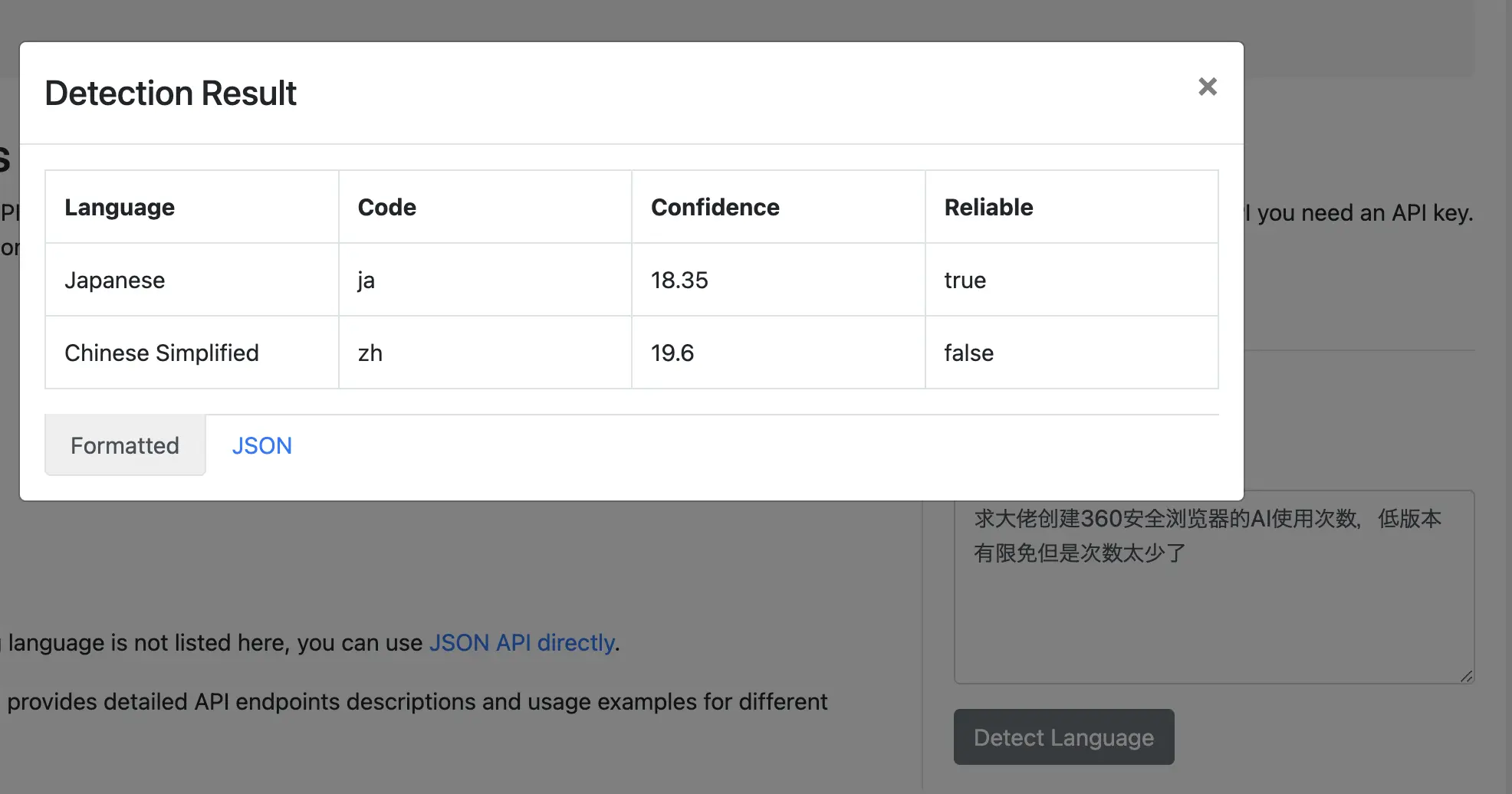
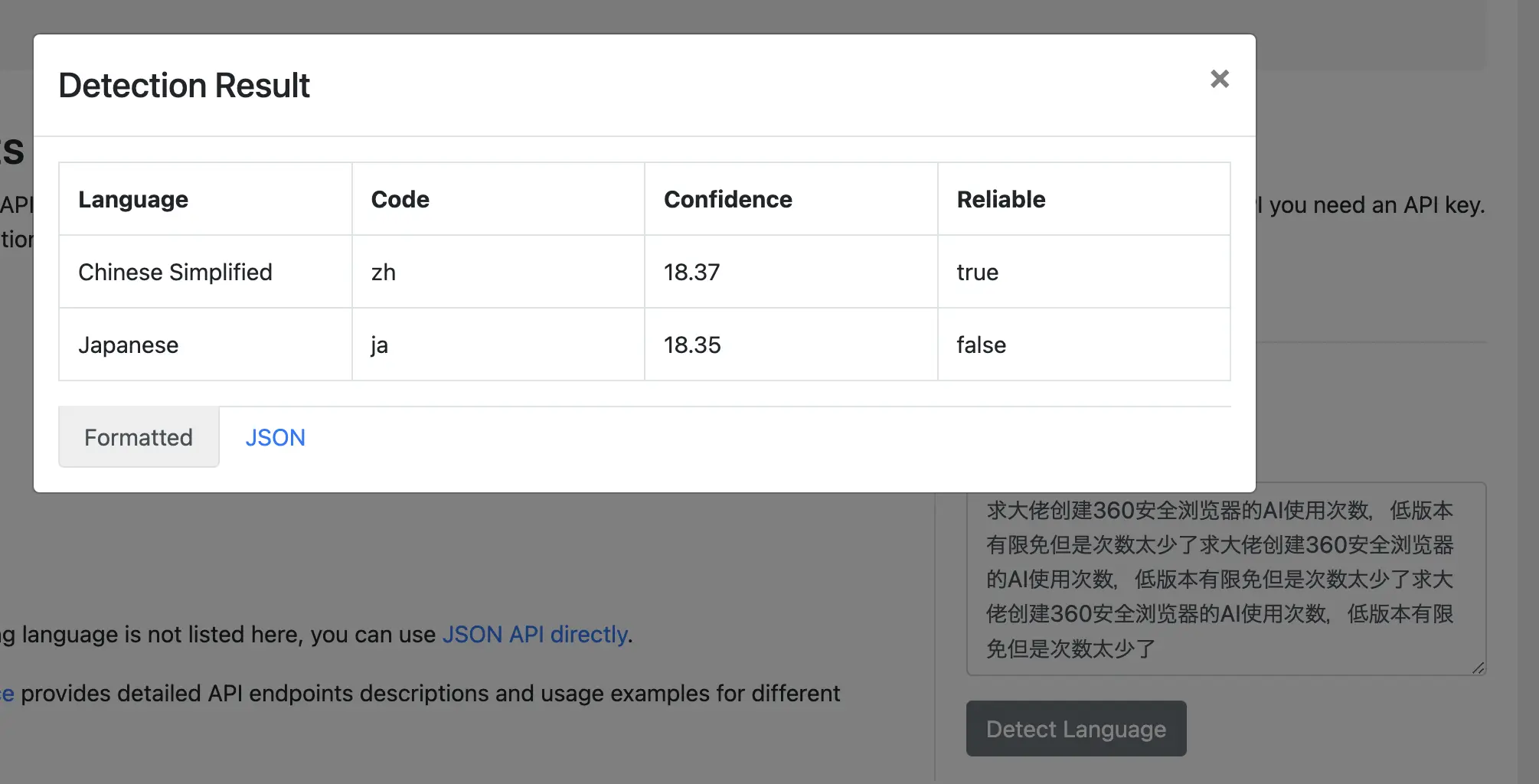
When the text length is insufficient, it will give the falsy result.
By repeating the same text, the result will be changed.
I think after taking into account both the title and the discussion text, the issue should get improved.
(As the text is sufficiently long)
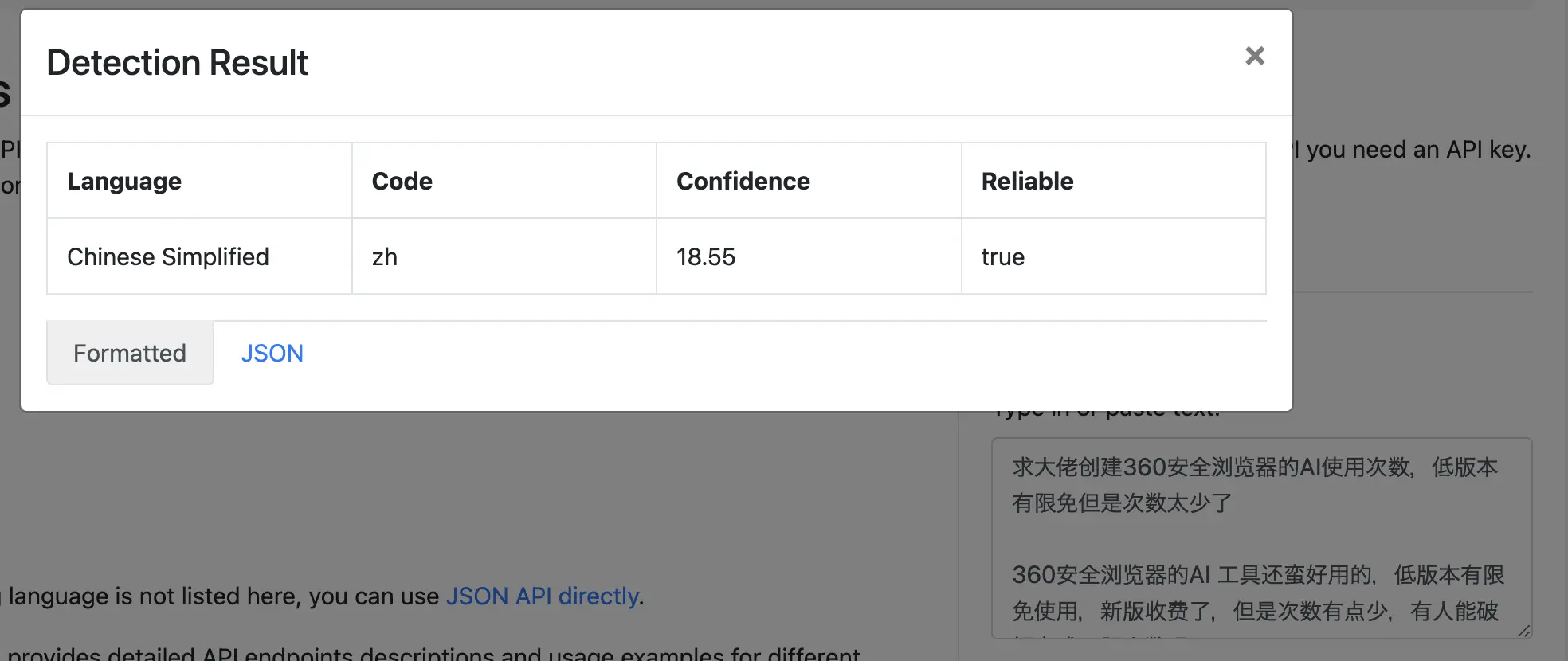
Or you can manually repeat the text before sending the query.
( original text + newline + original text)
Title only:
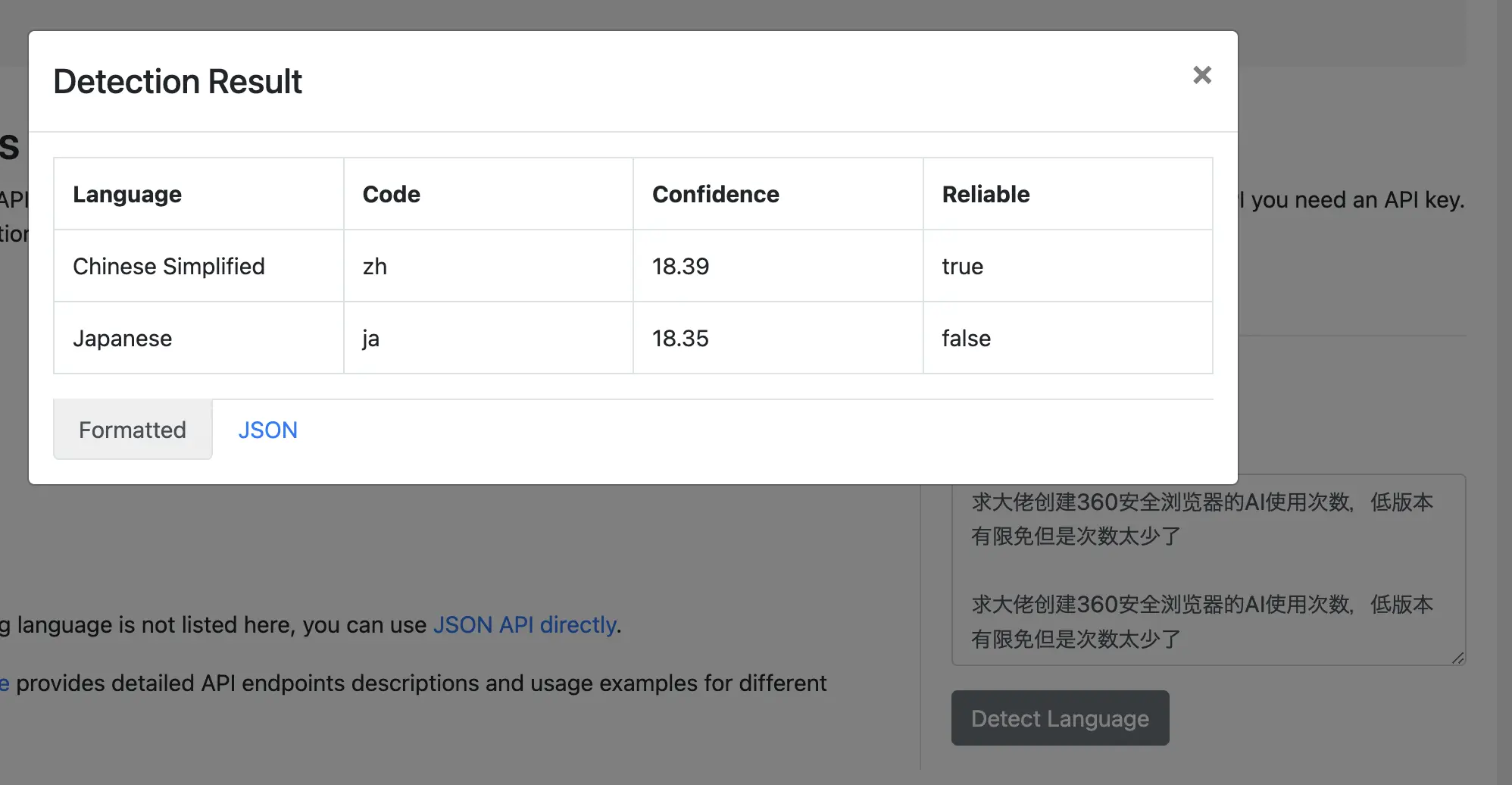
Title + Text:
This looks like it started happening with a change made in January 2024. I've rerun the detection on all discussions started since then that were flagged as Japanese and 15 got reclassified. Does the list look better now?
This looks like it started happening with a change made in January 2024. I've rerun the detection on all discussions started since then that were flagged as Japanese and 15 got reclassified. Does the list look better now?
?? I cannot find any difference.
And the discussion title + discussion text fix is already applied?
And how about the reliable value?
For example,
"第一次接触脚本,真滴黑科技" is Japanese (not reliable)
"这个可以有" is Chinese Simplified (reliable)
title: "网盘直链下载助手" is Chinese Simplified (reliable)
However, it is show shown under "日本語(ja)".
That is a discussion on a script, so it doesn't have its own title. Subsequent replies are not considered in this. So the only text that matters is the text of the first comment:
第一次接触脚本,真滴黑科技
and detectlanguage.com only returns Japanese for that.
That is a discussion on a script, so it doesn't have its own title. Subsequent replies are not considered in this. So the only text that matters is the text of the first comment:
第一次接触脚本,真滴黑科技
and detectlanguage.com only returns Japanese for that.
Can you add the filtering so that reliable = false will be filtered out from the listing?
I would rather use its best guess than to not assign a language at all.

According to the detectlanguage's FAQ, I don't think the only lang with reliable:false is best guess.
It's simply unclassified.
Just like you query a text with meaningless characters and ask for the language. From the characters, it can just detect it as English but actually it is not English.
Or, can you add an option or url param to filter out the reliable: false results?
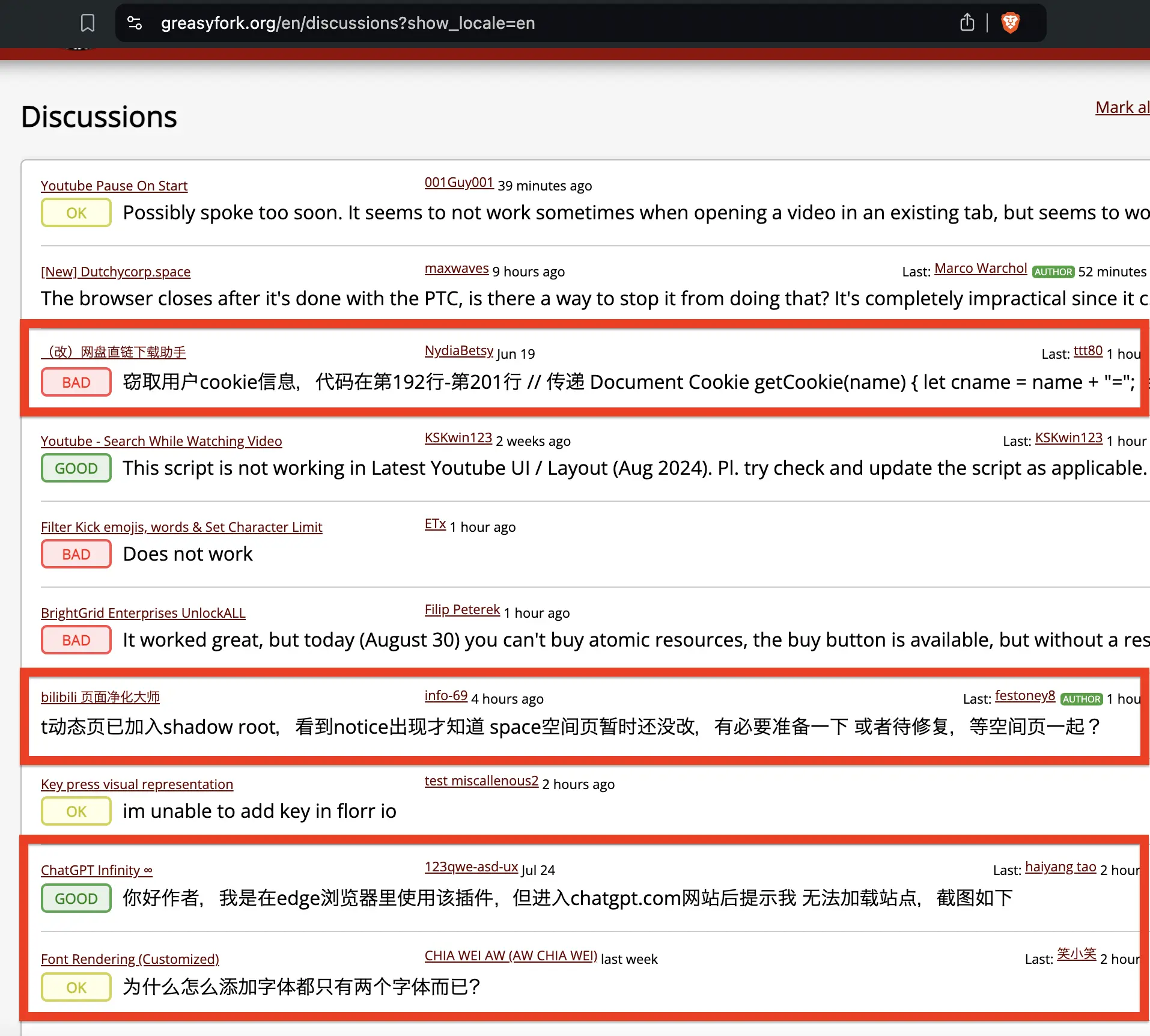
For English (https://greasyfork.org/en/discussions?show_locale=en), why Chinese results are shown?
Same for français
Users assign a Preferred locale to themselves on their settings https://greasyfork.org/en/ so /en/ could be used to know which language the user is likely using and typing.
For English (https://greasyfork.org/en/discussions?show_locale=en), why Chinese results are shown?
I did not go back and redetect the language for all discussions, just the Japanese-detected ones. I have a limited number of requests I can do in a day, so I can't rerun for everything.
Additionally, I would guess that it may be detecting code as English.
Users assign a Preferred locale to themselves on their settings https://greasyfork.org/en/ so /en/ could be used to know which language the user is likely using and typing.
That's what I considered doing in the case where detectlanguage.com returns multiple possibilities, but in the identified case (for this discussion), it's only returning one possibility. Doing so in this kind of scenario would likely lead to lots of errors going the other way - e.g. a user browses the site in Chinese but posts a discussion in English.
"a user browses the site in Chinese but posts a discussion in English."
Yes, I agree with you, but doesn't GF tries to redirect the user from chinese to /en/ if the user Preferred locale is /en/?
I thought that GF tried to do that... If GF doesn't do that I believe that it really should be doing it...
Yes, it will redirect to the preferred locale. But I'm saying specifically someone whose preferred locale is Chinese, but knows English and so sometimes does post in English. Or any other combo of languages.
Doing it just by the user's preferred locale will be wrong more often than what it's doing currently.
I did not go back and redetect the language for all discussions, just the Japanese-detected ones. I have a limited number of requests I can do in a day, so I can't rerun for everything.
Understood. When you do a re-run progressively, please save all the API results (how many languages detected, reliability for each detected lang, etc.). Then give url param option to filter-out by reliability. Thanks.
@Jason Lang Filter for Discussion Search is Broken.
https://greasyfork.org/en/discussions?show_locale=ja
To be honest, I don't understand how do you do the language detection for the comments.
If you cannot find a proper way to filter comments by language, you might just remove this feature.
As the screenshot suggested, Chinese comments are wrongly recognized as Japanese comments.